7 min read
Introduction: The "Reliability Gap" in LLMs
While Large Language Models (LLMs) have transformed how we interact with text, they often struggle with reasoning, memory, and long-term explainability. The real breakthrough comes with Knowledge Graphs: structured maps of entities and relationships that allow AI agents to reason, retrieve, and act with actual context.
However, most closed-source models perform poorly on the critical Text2Graph task, the process of turning unstructured text into a relational knowledge graph. After reviewing dozens of models, our team identified a significant "reliability gap". General-purpose models frequently fail to follow a strict schema, resulting in outputs that cannot be parsed or reused at scale. This page documents our journey in developing Lettria Perseus, a specialized model designed to eliminate hallucinations and set a new industry standard for document intelligence.
TL;DR
Our fine-tuned Perseus model achieves 30% higher accuracy and runs 400x faster than the leading general LLMs on knowledge extraction tasks. By moving from bulky general-purpose prompts to our new Text2KGBench-LettrIA standard—featuring 19 refined ontologies and 14,882 manually verified triples—we have finally achieved 100% schema reliability for enterprise-grade reasoning.
The Big Picture: Overall Model Ranking by Reliability
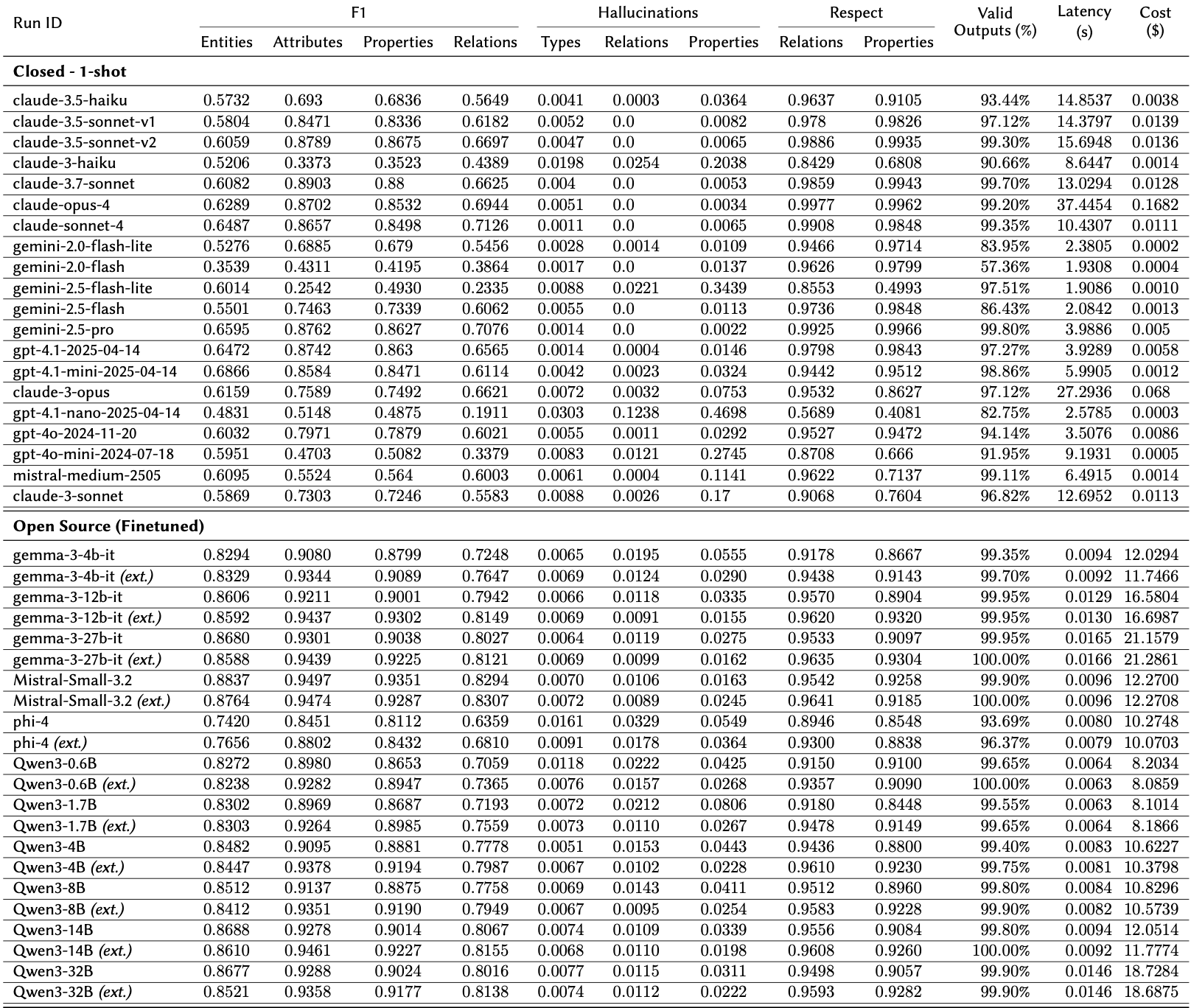
Our research includes a comprehensive review of 29 LLM runs, evaluating performance, quality, and operational efficiency. The single most important metric is Output Reliability (%), which measures the percentage of outputs that were perfectly valid and schema-compliant.
Key insight
A massive performance gap exists between purpose-built SFT models and general-purpose API models. While SFT models hit near-perfect reliability, smaller "Mini" or "Nano" models are unusable for this complex task.
Our Text2Graph Methodology: The Path to Perseus
Improve Data Quality: Text2KGBench-LettrIA
Current benchmarks like Text2KGBench often fall short due to data noise and structural gaps. We spent a year creating Text2KGBench-LettrIA:
- 19 Refined Ontologies: Domain-specific structures with precise typing for entities and attributes.
- 14,882 High-Quality Triples: A corpus of 4,860 sentences grounded strictly in the source text.
- Normalization: Dates, durations, and numbers were converted into machine-readable formats.
- Standardization: Corporate suffixes were cleaned and pronouns resolved to preserve textual fidelity.
Supervised Fine-Tuning (SFT)
We adapted our models using the Unsloth framework on Nvidia H100 GPUs .
- RDF vs. JSON: While RDF is traditional, its token overhead makes it less efficient. We transitioned to compact JSON triples to improve speed and input capacity.
- Training Strategies: We tested Classic, Extended (augmented with synthetic data), and Generalization (leave-one-out) strategies.
- Specialized Performance: Supervised Fine-Tuned (SFT) models achieve >98% Output Reliability and the highest F1 scores across the board.
Deep Dive 1: The SFT Champions (Gemma, Qwen, Mistral, Phi)
Our results demonstrate that specialized fine-tuning is in a class of its own.
- Near-Perfect Reliability: All 10 SFT models achieved >98% reliability, with Mistral Small 3.2 hitting 99.9% and Qwen 3 32B reaching 99.95%.
- Accuracy Leaders: These models lead in all core metrics, specifically Attribute Extraction F1 (0.93 - 0.95) and Entities Extraction F1 (0.89 - 0.92).
- The Trade-off: Their only minor weakness is a slightly higher rate of minor hallucinations compared to top API models; for instance, Qwen 3 0.6B has a 2.53% Relation Hallucination Rate.
- Optimal Path: For production systems where accuracy is paramount, fine-tuning a specialized model like Gemma 27B or Qwen 32B is the optimal path.

Deep Dive 2: Top-Tier API Models - The Battle of the Titans
For organizations relying on API-based solutions, there are clear winners and high-cost traps.
- GPT 4.1: This model is a surprisingly strong contender, boasting the highest reliability and fastest speed in the top tier for a moderate cost.
- Gemini 2.5 Pro: The most cost-effective of the "Pro/Opus" class, showing strong performance with zero hallucinations or schema errors, though it is very slow.
- Claude 4.1 Opus: While it provides top-tier F1 scores, it comes at an astronomical cost—nearly 10x the price of Gemini Pro for similar reliability.
- Claude 4 Sonnet: A strong all-rounder, yet significantly more expensive than GPT 4.1 for lower reliability.
Deep Dive 3: The Mid-Range & The Pitfalls of "Mini" Models
This group exhibits a sharp drop-off in reliability due to consistent structural failures.
- GPT 4o: Suffers from a 56.41% Extra Prefix Rate, suggesting severe formatting issues.
- The "Nano" Trap: GPT 4.1 Nano and Gemini Nano are unusable for this task, with reliability scores of 10.92% and 3.03%, failing structurally on almost every attempt.
- Gemini Flash-Lite: The "no-thinking" version shows a massive hallucination problem (14.8% Property Hallucinations).
- The Verdict: Smaller, cheaper model variants are simply not equipped for complex graph extraction; their failure rates negate any cost or speed benefits.
Performance Benchmarks: Lettria Perseus vs. others
Output Reliability
Output reliability is critical. A large share of errors comes from this stage: when the graph does not follow the defined ontology, the results cannot be parsed correctly or reused at scale. This makes downstream automation unreliable and drives up the cost of manual correction.
Output reliability among models
Latency Benchmark
Our model achieved ultra-low latency, delivering structured outputs in under 20 milliseconds, orders of magnitude faster than proprietary API models, which average 2 to 37 seconds per query. This speed makes our fine-tuned model ideal for high-volume, real-time applications where response time directly impacts user experience and business performance.
Latency Benchmark
Deep Dive: Extraction and Classification Building Blocks
A reliable Knowledge Graph requires mastering the core building blocks:
- Entities: The nodes representing people, organizations, or concepts.
- Properties: The name of the characteristic (e.g., "Color" or "Age").
- Attributes: The specific data values assigned to properties.
- Relations: The edges linking entities to each other.
The charts below present F1 scores comparing Lettria Perseus with state-of-the-art LLMs. Results highlight the advantage of a model trained specifically for complex document understanding, where precision and recall directly impact compliance and efficiency. You'll find all the detailed results comparing over 40 models at the bottom of this page.



%201.png)
In conclusion
With Perseus, Lettria delivers the best fine-tuned Text-to-Graph model built for regulated industries.
- Accuracy – Entity F1 up to 0.88, outperforming GPT-4, Claude Sonnet 4 and Gemini 2.5 Pro
- Privacy – Self-hosted, your sensitive data never leaves your environment
- Speed – Inference under 20ms
- Reliability – 99–100% schema-valid outputs
- Scalable – 19 ontologies, 14,882 curated triples
.png)
Strategic Findings & Recommendations
Finding 1: The Cost of Quality
The most expensive model (Claude Opus) is not necessarily the best. SFT delivers superior performance at a mid-range price point ($11–$25), offering the highest return on investment. For example, Gemma 3 27B achieved better results than Gemini 2.5 Pro for a lower total cost.
Finding 2: The "Mini" and "Nano" Trap
Smaller model variants like GPT-4o Mini and Gemini Flash-Lite consistently exhibit low reliability (<40%) and high error rates. They suffer from structural failures like Invalid JSON and high hallucination rates, making them unusable for complex graph extraction.
Strategic Recommendations
- For Mission-Critical Systems: Invest in Supervised Fine-Tuning (SFT). Models like Mistral Small 3.2 or Qwen 3 32B hit up to 99.95% reliability .
- For High-Quality API Solutions: Use GPT 4.1 for speed and value or Gemini 2.5 Pro for the highest non-fine-tuned quality.
- For Rapid Prototyping: Use Claude 3.5 Haiku or Gemini 2.5 Flash .
- To Avoid: Do not use "Mini" or "Nano" variants; their high failure rates negate any cost or speed benefits.
Why Business Leaders Care
Knowledge Graphs enable GraphRAG for precise, structured queries beyond vector search, explainable AI with decisions grounded in transparent facts, regulation and compliance to ensure outputs follow business rules, and next-gen enterprise AI :
- Build AI you can trust: Make decisions in transparent, verifiable knowledge graphs instead of black-box predictions.
- Unlock enterprise knowledge: Connect silos of unstructured text into a single, searchable knowledge fabric.
- Ensure regulatory compliance: Simplify audits and reporting with traceable, explainable data flows.
- Drive measurable ROI: Lower reliance on costly APIs and manual processes with scalable in-house intelligence.
Why Technical Leaders Care
Technical teams gain a robust, reliable stack for enterprise-grade knowledge graph generation and agent building:
- Performance edge over proprietary APIs: Deliver higher accuracy with fine-tuned, domain-specific training.
- Schema-guided extraction for reliability: Minimize error propagation in downstream analytics and workflows.
- Scalable deployment with predictable costs: Easily adapt to growing data volumes without unpredictable pricing spikes.
- Reduced hallucinations & guaranteed valid outputs: Every answer is backed by verifiable entities and relationships.
Experience the Future of Agents
Lettria is building the bridge from today’s LLMs to tomorrow’s trustworthy enterprise agents. With Perseus, organizations can combine the entire Lettria technology stack into a seamless pipeline:
- Document Parsing – transform raw, unstructured documents into clean, structured data that’s ready for analysis.
Read more: Reconstructing logical reading order Parsing complex tables · Parsing multipage documents without losing context
- Ontology Building – design custom taxonomies and hierarchical knowledge models to ensure semantic consistency across all data. This step guarantees that outputs align with industry-specific logic and compliance requirements.
Read more: Beyond the black box: how semantics & ontology make AI explainable
- GraphRAG – connect parsed documents and ontologies into powerful knowledge graphs that fuel explainable reasoning, precise retrieval, and enterprise-grade AI applications.
Read more: Graph-constrained reasoning · Introduction to knowledge graph completion · Bridging knowledge graphs and ontologies
By linking these components, Lettria delivers a complete solution for extracting, structuring, and operationalizing enterprise knowledge, a foundation that makes AI both trustworthy and scalable.
Detailed results
Want to see Lettria Perseus in action?
If your company wants to use transparent, verifiable AI to improve performance, reach out to set up your personalized demo. And if you have other questions, on implementation, pricing please don’t hesitate to ask.